library(tidyr)
library(dplyr)
library(forcats)
library(stringr)
library(ggplot2)
library(scales)
library(patchwork)
library(tibble)
library(purrr)
library(furrr)
library(faux)
library(janitor)
#library(afex)
# set up parallelization
plan(multisession)16 p-hacking via different forms of selecting reporting ✎ Rough draft
16.1 Overview
p-hacking is increasing the false-positive rate through analytic choices. These choices are often a) flexible, in that many different options might be tried until significance is found (Gelman called this the “Garden of Forking Paths”), and b) undisclosed. However, it need not be either in a given instance: perhaps the very first analytic strategy tried produces the significant result (but if it hadn’t, other strategies would have been tried), or perhaps the author fully discloses the analytic choices but does not make clear to the reader how this undermines the severity of the test (i.e., it takes a very close reading to understand that the results present weak evidence, or the verbal conclusions oversell this).
p-hacking can occur because of the uniform distribution of p-values under the null hypothesis. Because all values are equally likely, you just have to keep rolling the dice to eventually find p < .05.
This lesson illustrates a few different examples of one broad form of p-hacking called selective reporting.
16.2 Dependencies
16.3 Selective reporting of studies
If I run two experiments, and only report the one that “works”, I will increase the false positive rate across studies. Perhaps it is because one really is better designed etc than the other. Or perhaps its just a false positive.
What would you guess the false positive rate is for two studies?
Let’s simulate it.
16.3.1 Run simulation
generate_data <- function(n_per_condition,
mean_control,
mean_intervention,
sd) {
data_control <-
tibble(condition = "control",
score = rnorm(n = n_per_condition, mean = mean_control, sd = sd))
data_intervention <-
tibble(condition = "intervention",
score = rnorm(n = n_per_condition, mean = mean_intervention, sd = sd))
data_combined <- bind_rows(data_control,
data_intervention)
return(data_combined)
}
# define data analysis function ----
analyze <- function(data) {
students_ttest <- t.test(formula = score ~ condition,
data = data,
var.equal = TRUE,
alternative = "two.sided")
res <- tibble(p = students_ttest$p.value)
return(res)
}
# define experiment parameters ----
experiment_parameters <- expand_grid(
n_per_condition = 100,
mean_control = 0,
mean_intervention = 0,
sd = 1,
iteration = 1:1000
)
# run simulation ----
set.seed(42)
simulation <-
# using the experiment parameters
experiment_parameters |>
# generate data using the data generating function and the parameters relevant to data generation
mutate(generated_data_study1 = future_pmap(.l = list(n_per_condition,
mean_control,
mean_intervention,
sd),
.f = generate_data,
.progress = TRUE,
.options = furrr_options(seed = TRUE))) |>
mutate(generated_data_study2 = future_pmap(.l = list(n_per_condition,
mean_control,
mean_intervention,
sd),
.f = generate_data,
.progress = TRUE,
.options = furrr_options(seed = TRUE))) |>
# apply the analysis function to the generated data using the parameters relevant to analysis
mutate(results_study1 = future_pmap(.l = list(data = generated_data_study1),
.f = analyze,
.progress = TRUE,
.options = furrr_options(seed = TRUE))) |>
mutate(results_study2 = future_pmap(.l = list(data = generated_data_study2),
.f = analyze,
.progress = TRUE,
.options = furrr_options(seed = TRUE)))
# summarise simulation results over the iterations ----
simulation_summary <- simulation |>
# unnest and rename
unnest(results_study1) |>
rename(p_study1 = p) |>
unnest(results_study2) |>
rename(p_study2 = p) |>
# simulate flexible reporting
mutate(p_hacked = ifelse(p_study1 < .05, p_study1, p_study2)) |>
# summarize
summarize(prop_sig_study1 = mean(p_study1 < .05),
prop_sig_study2 = mean(p_study2 < .05),
prop_sig_hacked = mean(p_hacked < .05),
.groups = "drop") |>
pivot_longer(cols = everything(),
names_to = "Source",
values_to = "proportion_significant") |>
mutate(Source = str_remove(Source, "prop_sig_"))16.3.2 Results
simulation_summary |>
mutate_if(is.numeric, round_half_up, digits = 2) | Source | proportion_significant |
|---|---|
| study1 | 0.04 |
| study2 | 0.05 |
| hacked | 0.09 |
16.3.3 Conclusions
The false positive rate for two studies is ~10%, because each study has a 5% false positive rate.
16.3.4 Exercise: extend the simulation
Extend the simulation so that four studies are run. What do you expect the false positive rate to be? What do you find?
16.3.5 Solution
generate_data <- function(n_per_condition,
mean_control,
mean_intervention,
sd) {
data_control <-
tibble(condition = "control",
score = rnorm(n = n_per_condition, mean = mean_control, sd = sd))
data_intervention <-
tibble(condition = "intervention",
score = rnorm(n = n_per_condition, mean = mean_intervention, sd = sd))
data_combined <- bind_rows(data_control,
data_intervention)
return(data_combined)
}
# define data analysis function ----
analyze <- function(data) {
students_ttest <- t.test(formula = score ~ condition,
data = data,
var.equal = TRUE,
alternative = "two.sided")
res <- tibble(p = students_ttest$p.value)
return(res)
}
# define experiment parameters ----
experiment_parameters <- expand_grid(
n_per_condition = 100,
mean_control = 0,
mean_intervention = 0,
sd = 1,
iteration = 1:1000
)
# run simulation ----
set.seed(42)
simulation <-
# using the experiment parameters
experiment_parameters |>
# generate data using the data generating function and the parameters relevant to data generation
mutate(generated_data_study1 = future_pmap(.l = list(n_per_condition = n_per_condition,
mean_control = mean_control,
mean_intervention = mean_intervention,
sd = sd),
.f = generate_data,
.progress = TRUE,
.options = furrr_options(seed = TRUE))) |>
mutate(generated_data_study2 = future_pmap(.l = list(n_per_condition = n_per_condition,
mean_control = mean_control,
mean_intervention = mean_intervention,
sd = sd),
.f = generate_data,
.progress = TRUE,
.options = furrr_options(seed = TRUE))) |>
mutate(generated_data_study3 = future_pmap(.l = list(n_per_condition = n_per_condition,
mean_control = mean_control,
mean_intervention = mean_intervention,
sd = sd),
.f = generate_data,
.progress = TRUE,
.options = furrr_options(seed = TRUE))) |>
mutate(generated_data_study4 = future_pmap(.l = list(n_per_condition = n_per_condition,
mean_control = mean_control,
mean_intervention = mean_intervention,
sd = sd),
.f = generate_data,
.progress = TRUE,
.options = furrr_options(seed = TRUE))) |>
# apply the analysis function to the generated data using the parameters relevant to analysis
mutate(results_study1 = future_pmap(.l = list(data = generated_data_study1),
analyze,
.progress = TRUE,
.options = furrr_options(seed = TRUE))) |>
mutate(results_study2 = future_pmap(.l = list(data = generated_data_study2),
analyze,
.progress = TRUE,
.options = furrr_options(seed = TRUE))) |>
mutate(results_study3 = future_pmap(.l = list(data = generated_data_study3),
analyze,
.progress = TRUE,
.options = furrr_options(seed = TRUE))) |>
mutate(results_study4 = future_pmap(.l = list(data = generated_data_study4),
analyze,
.progress = TRUE,
.options = furrr_options(seed = TRUE)))
# summarise simulation results over the iterations ----
simulation_summary <- simulation |>
# unnest and rename
unnest(results_study1) |>
rename(p_study1 = p) |>
unnest(results_study2) |>
rename(p_study2 = p) |>
unnest(results_study3) |>
rename(p_study3 = p) |>
unnest(results_study4) |>
rename(p_study4 = p) |>
# simulate flexible reporting
mutate(p_hacked = case_when(p_study1 < .05 ~ p_study1,
p_study2 < .05 ~ p_study2,
p_study3 < .05 ~ p_study3,
TRUE ~ p_study4)) |>
# summarize
summarize(prop_sig_study1 = mean(p_study1 < .05),
prop_sig_study2 = mean(p_study2 < .05),
prop_sig_study3 = mean(p_study3 < .05),
prop_sig_study4 = mean(p_study4 < .05),
prop_sig_hacked = mean(p_hacked < .05),
.groups = "drop") |>
pivot_longer(cols = everything(),
names_to = "Source",
values_to = "proportion_significant") |>
mutate(Source = str_remove(Source, "prop_sig_"))
simulation_summary |>
mutate_if(is.numeric, round_half_up, digits = 2)| Source | proportion_significant |
|---|---|
| study1 | 0.04 |
| study2 | 0.05 |
| study3 | 0.04 |
| study4 | 0.05 |
| hacked | 0.17 |
16.5 Selective reporting of correlated outcomes
Aka “outcome switching”, which is both common and problematic in clinical trials.
There are of course situations where the tests are not independent, and this makes it more complicated to understand the FPR. For example, imagine I am interested in the impact of CBT on depression, but I include multiple measures of depression and report the one that ‘worked’.
16.5.1 Generate correlated data
We haven’t simulated correlated data before so lets do that first.
set.seed(42)
dat <-
faux::rnorm_multi(n = 1000,
mu = c(0, 0),
sd = c(1, 1),
r = -0.7,
varnames = c("var1", "var2"))
cor(dat) var1 var2
var1 1.0000000 -0.7083632
var2 -0.7083632 1.0000000ggplot(dat, aes(var1, var2)) +
geom_point(alpha = 0.4) +
theme_linedraw()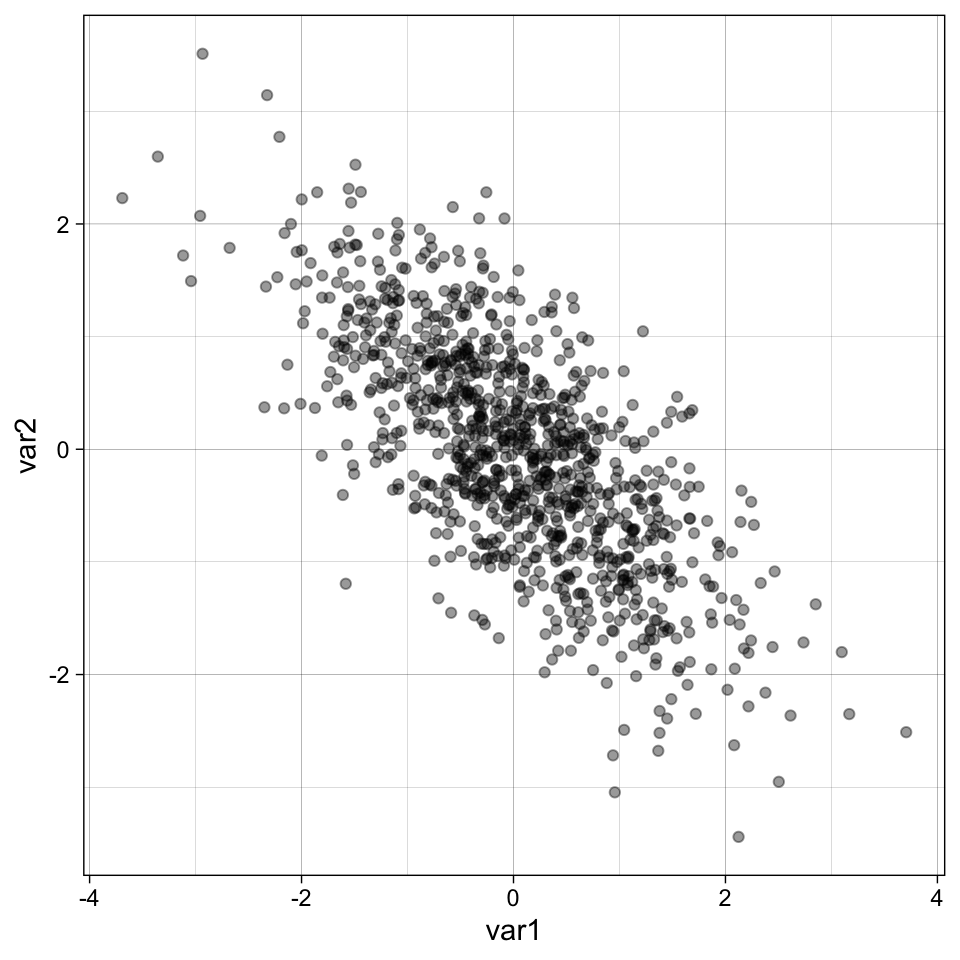
16.5.2 Generate data
Correlated outcomes, known groups differences.
generate_data <- function(n_per_condition,
r_between_outcomes,
mu_control, # vector of length 1 or k
mu_intervention, # vector of length 1 or k
sigma_control = 1, # vector of length 1 or k
sigma_intervention = 1) { # vector of length 1 or k
# generate data by condition
data_control <-
rnorm_multi(n = n_per_condition,
mu = mu_control,
sd = sigma_control,
r = r_between_outcomes,
varnames = c("outcome1", "outcome2", "outcome3")) |>
mutate(condition = "Control")
data_intervention <-
rnorm_multi(n = n_per_condition,
mu = mu_intervention,
sd = sigma_intervention,
r = r_between_outcomes,
varnames = c("outcome1", "outcome2", "outcome3")) |>
mutate(condition = "Intervention")
# combine
data_combined <-
bind_rows(data_control,
data_intervention) |>
mutate(condition = fct_relevel(condition, "Intervention", "Control"))
return(data_combined)
}Check the function works
# simulate data
set.seed(42)
dat <- generate_data(n_per_condition = 100000,
r_between_outcomes = 0.6,
mu_control = 0,
mu_intervention = 1.5)
# parameter recovery
dat |>
group_by(condition) |>
summarize(mean_outcome1 = mean(outcome1),
mean_outcome2 = mean(outcome2),
correlation = cor(outcome1, outcome2)) |>
mutate_if(is.numeric, round_half_up, digits = 2)| condition | mean_outcome1 | mean_outcome2 | correlation |
|---|---|---|---|
| Intervention | 1.5 | 1.5 | 0.6 |
| Control | 0.0 | 0.0 | 0.6 |
16.5.3 Run simulation
# define data analysis function ----
analyze <- function(data, outcome) {
# if you want to specify a column as an input, use rename()+{{}} to rename it before analysis
data_renamed <- data |>
rename(score = {{ outcome }})
students_ttest <- t.test(formula = score ~ condition,
data = data_renamed,
var.equal = TRUE,
alternative = "two.sided")
res <- tibble(p = students_ttest$p.value)
return(res)
}
# define experiment parameters ----
experiment_parameters <- expand_grid(
n_per_condition = 50,
r_between_outcomes = c(0, .1, .2, .3, .4, .5, .6, .7, .8, .9, .99),
mu_control = 0,
mu_intervention = 0,
iteration = 1:20000
)
# run simulation ----
set.seed(42)
simulation <-
# using the experiment parameters
experiment_parameters |>
# generate data using the data generating function and the parameters relevant to data generation
mutate(generated_data = future_pmap(.l = list(n_per_condition,
r_between_outcomes,
mu_control,
mu_intervention),
.f = generate_data,
.progress = TRUE,
.options = furrr_options(seed = TRUE))) |>
# apply the analysis function to the generated data using the parameters relevant to analysis
mutate(results_outcome1 = future_pmap(.l = list(data = generated_data,
outcome = "outcome1"),
.f = analyze,
.progress = TRUE,
.options = furrr_options(seed = TRUE)),
results_outcome2 = future_pmap(.l = list(data = generated_data,
outcome = "outcome2"),
.f = analyze,
.progress = TRUE,
.options = furrr_options(seed = TRUE)),
results_outcome3 = future_pmap(.l = list(data = generated_data,
outcome = "outcome3"),
.f = analyze,
.progress = TRUE,
.options = furrr_options(seed = TRUE)))
# summarise simulation results over the iterations ----
simulation_summary <- simulation |>
# unnest and rename
unnest(results_outcome1) |>
rename(outcome1_p = p) |>
unnest(results_outcome2) |>
rename(outcome2_p = p) |>
unnest(results_outcome3) |>
rename(outcome3_p = p) |>
# flag whether each outcome, and at least one outcome, was significant
mutate(sig_outcome1 = outcome1_p < .05,
sig_outcome2 = outcome2_p < .05,
sig_outcome3 = outcome3_p < .05,
sig_at_least_one = sig_outcome1 | sig_outcome2 | sig_outcome3) |>
# summarize across iterations: empirical detection rates
group_by(n_per_condition,
r_between_outcomes,
mu_control,
mu_intervention) |>
summarize(prop_sig_outcome1 = mean(sig_outcome1),
prop_sig_outcome2 = mean(sig_outcome2),
prop_sig_outcome3 = mean(sig_outcome3),
prop_sig_at_least_one = mean(sig_at_least_one),
.groups = "drop")16.5.4 Results
Empirical false positive rates as a function of the true correlation between outcomes. prop_sig_at_least_one is the empirical detection rate — the proportion of iterations in which at least one of the two outcomes reached p < .05, i.e. what a researcher who switches outcomes would report as “significant”.
simulation_summary |>
mutate_if(is.numeric, round_half_up, digits = 3)| n_per_condition | r_between_outcomes | mu_control | mu_intervention | prop_sig_outcome1 | prop_sig_outcome2 | prop_sig_outcome3 | prop_sig_at_least_one |
|---|---|---|---|---|---|---|---|
| 50 | 0.00 | 0 | 0 | 0.05 | 0.05 | 0.05 | 0.15 |
| 50 | 0.10 | 0 | 0 | 0.05 | 0.05 | 0.05 | 0.14 |
| 50 | 0.20 | 0 | 0 | 0.05 | 0.05 | 0.05 | 0.14 |
| 50 | 0.30 | 0 | 0 | 0.05 | 0.05 | 0.05 | 0.14 |
| 50 | 0.40 | 0 | 0 | 0.05 | 0.05 | 0.05 | 0.14 |
| 50 | 0.50 | 0 | 0 | 0.05 | 0.05 | 0.05 | 0.13 |
| 50 | 0.60 | 0 | 0 | 0.05 | 0.05 | 0.05 | 0.12 |
| 50 | 0.70 | 0 | 0 | 0.05 | 0.05 | 0.05 | 0.11 |
| 50 | 0.80 | 0 | 0 | 0.05 | 0.05 | 0.05 | 0.09 |
| 50 | 0.90 | 0 | 0 | 0.05 | 0.05 | 0.05 | 0.08 |
| 50 | 0.99 | 0 | 0 | 0.05 | 0.05 | 0.05 | 0.06 |
ggplot(simulation_summary, aes(r_between_outcomes, prop_sig_outcome1)) +
geom_hline(yintercept = 0.05, linetype = "dotted") +
geom_point() +
geom_line() +
scale_x_continuous(breaks = breaks_pretty(n = 9), name = "True correlation between outcomes") +
scale_y_continuous(limits = c(0, .2), breaks = breaks_pretty(n = 5), name = "Empirical Detection Rate\n(outcome 1)") +
theme_linedraw() +
scale_color_viridis_d(begin = 0.2, end = 0.8)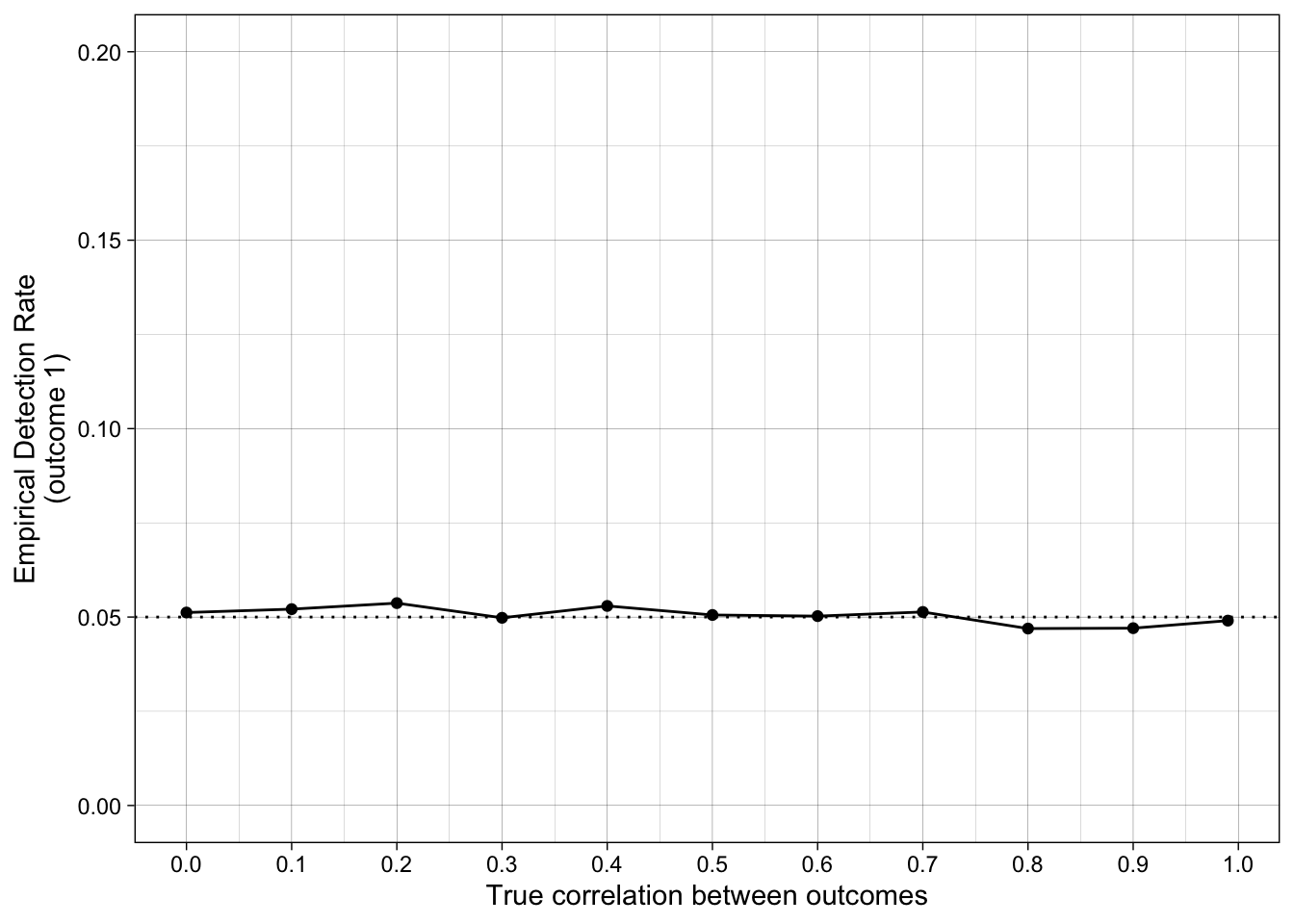
ggplot(simulation_summary, aes(r_between_outcomes, prop_sig_outcome2)) +
geom_hline(yintercept = 0.05, linetype = "dotted") +
geom_point() +
geom_line() +
scale_x_continuous(breaks = breaks_pretty(n = 9), name = "True correlation between outcomes") +
scale_y_continuous(limits = c(0, .2), breaks = breaks_pretty(n = 5), name = "Empirical Detection Rate\n(outcome 2)") +
theme_linedraw() +
scale_color_viridis_d(begin = 0.2, end = 0.8)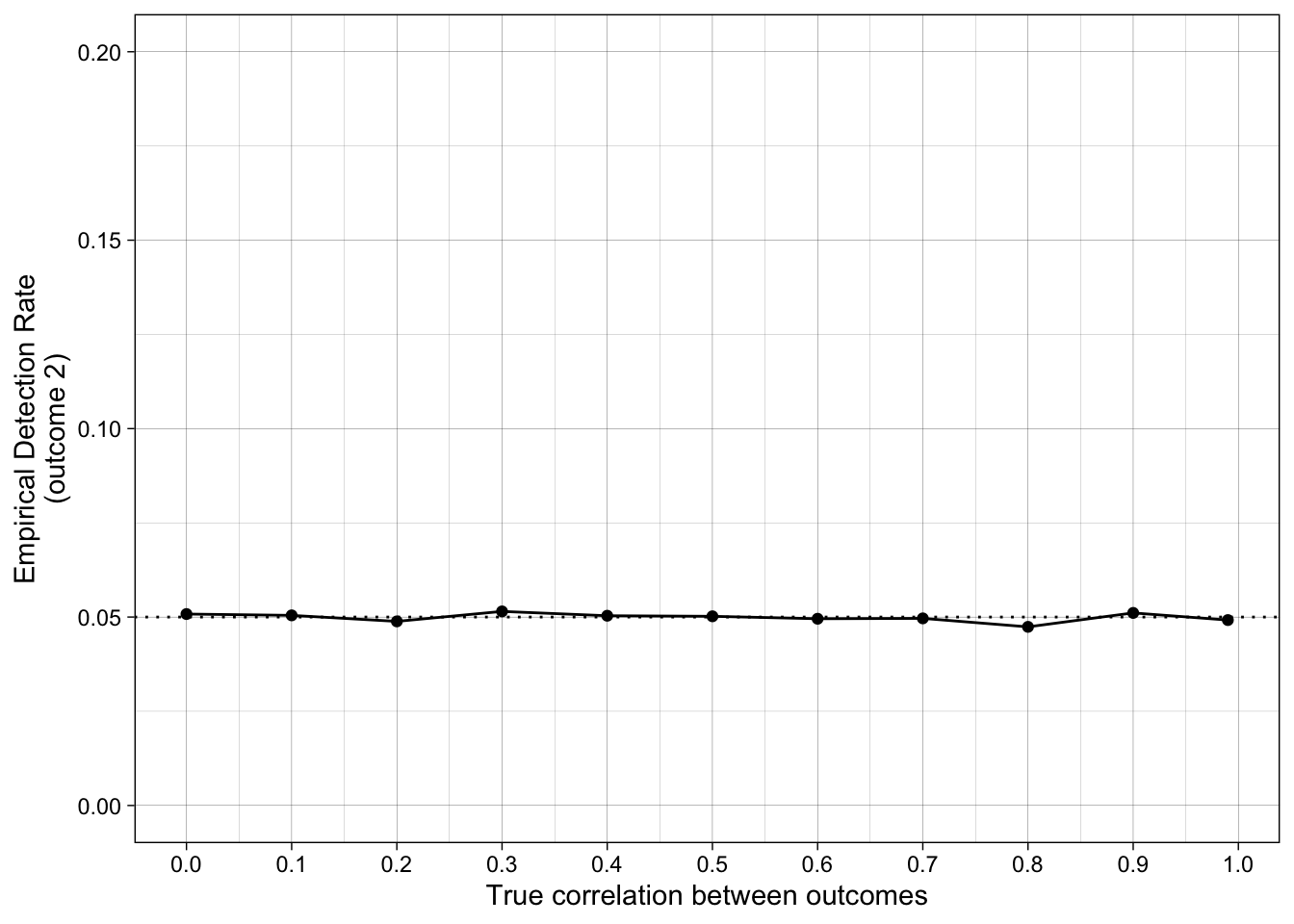
ggplot(simulation_summary, aes(r_between_outcomes, prop_sig_outcome3)) +
geom_hline(yintercept = 0.05, linetype = "dotted") +
geom_point() +
geom_line() +
scale_x_continuous(breaks = breaks_pretty(n = 9), name = "True correlation between outcomes") +
scale_y_continuous(limits = c(0, .2), breaks = breaks_pretty(n = 5), name = "Empirical Detection Rate\n(outcome 3)") +
theme_linedraw() +
scale_color_viridis_d(begin = 0.2, end = 0.8)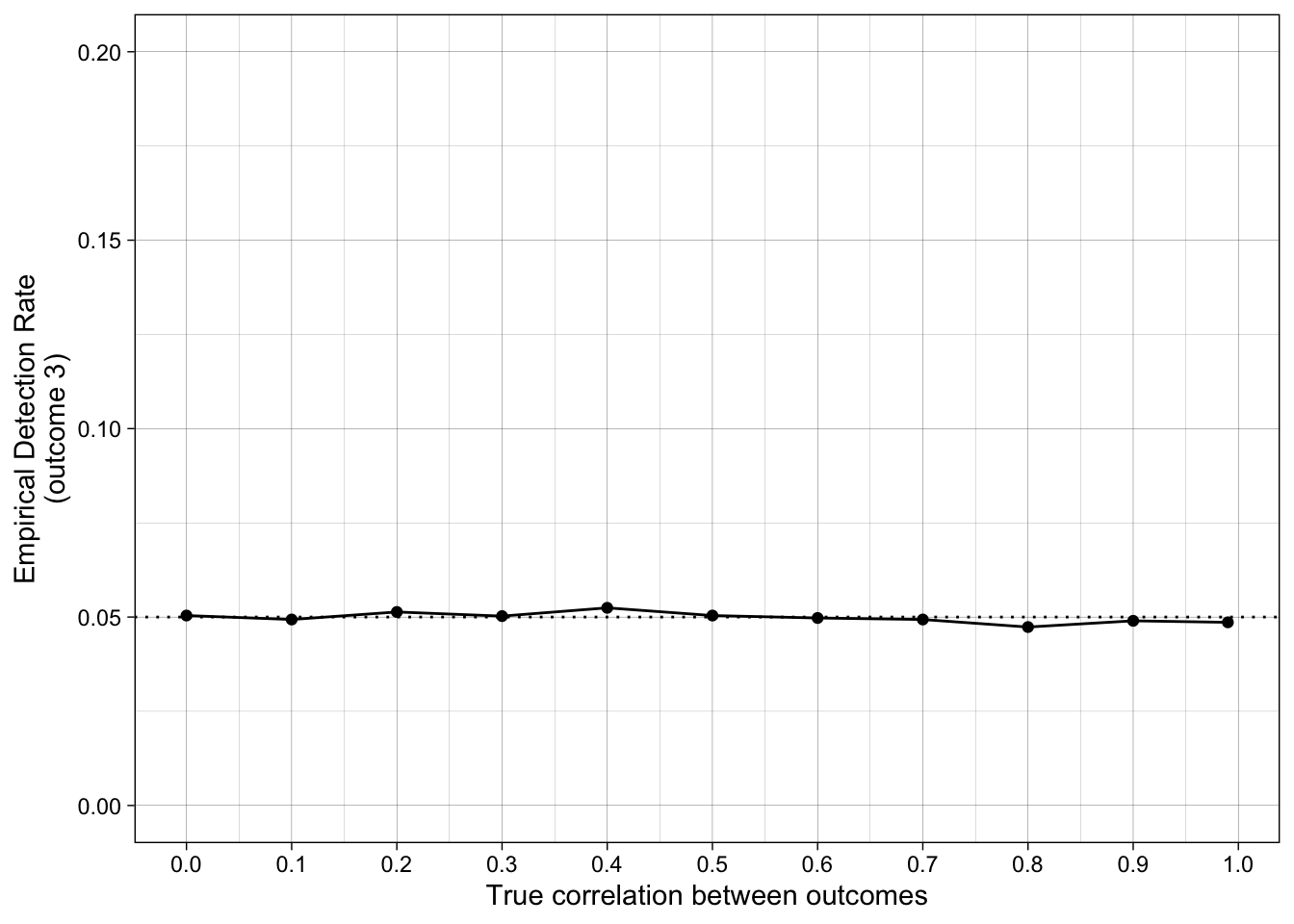
ggplot(simulation_summary, aes(r_between_outcomes, prop_sig_at_least_one)) +
geom_hline(yintercept = 0.05, linetype = "dotted") +
geom_point() +
geom_line() +
scale_x_continuous(breaks = breaks_pretty(n = 9), name = "True correlation between outcomes") +
scale_y_continuous(limits = c(0, .2), breaks = breaks_pretty(n = 5), name = "Empirical Detection Rate\n(at least one outcome significant)") +
theme_linedraw() +
scale_color_viridis_d(begin = 0.2, end = 0.8)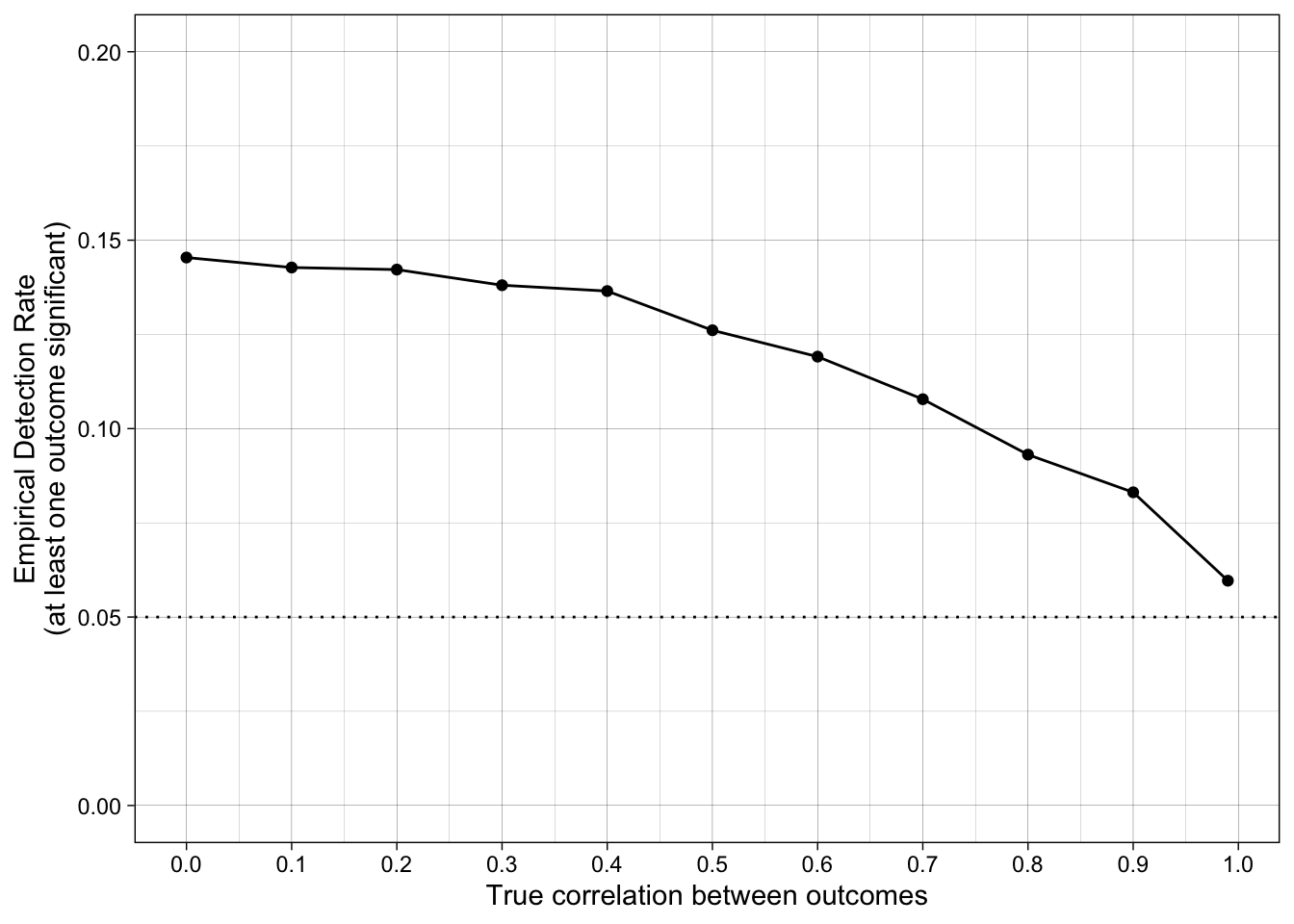
16.5.5 Conclusions
How does the false positive rate change when the outcome measures are correlated?
What perverse incentive does this set up for researchers?
16.6 Check your learning
If authors reported the results of all outcome variables (and not just the ones that ‘worked’):
- Would this problem be improved?
- Would this problem be completely solved?
16.7 In-class exercises
Without writing any code, design and describe the necessary components of simulations that quantify the the effect of the following p-hacking strategies on the false positive rate (i.e., empirical detection rate when true difference in means is 0)
- Flexibility in whether the DV is log transformed or not.
- Flexibility in whether to exclude DV outliers or not (e.g., >±1SD from mean).
- Flexibility calculating a median split for the DV or not.
16.8 Readings
- Stefan, A. M. and Schönbrodt F. D. (2023) Big little lies: a compendium and simulation of p-hacking strategies. Royal Society Open Science. 10220346 http://doi.org/10.1098/rsos.220346